
HyperFlow AIのSuper Node
変化し続けるAI環境の中でもワークフローの中核構造が揺らがないように設計された、HyperFlowの役割中心アーキテクチャを紹介します。
Super Nodeアーキテクチャが実現する柔軟なAIワークフロー
生成AIアプリケーション開発において重要なのは、単に複数のサービスを接続することではありません。より重要なのは、変化し続けるAI環境の中でも、ワークフローの中核構造が揺らがないように設計することです。HyperFlow AIはそのために、サービス中心のノード構造ではなく、役割中心のSuper Nodeアーキテクチャを採用しました。
AI開発で最も頻繁に発生する問題
生成AI技術は非常に速いスピードで変化しています。昨日までは最適だと思われていたモデルが、今日にはより高価になったり、より優れた代替モデルが登場したり、特定のAPIポリシーが変更されたりすることは、もはや珍しいことではありません。
例えば、1つのAIチャットボットを作る場合でも、内部にはさまざまな構成要素が必要です。
LLMモデル
エンベディングモデル
ベクトルデータベース
文書検索ロジック
プロンプトテンプレート
出力形式の制御
コストおよびパフォーマンス管理
ユーザー入力処理
問題は、これらの各要素が特定のサービスに強く結びついている場合に発生します。最初はOpenAIを基準に構築したとしても、後からClaudeやGeminiに切り替えたくなることがあります。特定のベクトルデータベースを使用していたものの、コストや性能の問題によって別のデータベースへ移行する必要が出てくる場合もあります。
従来の方式では、このような変更は単純な差し替えだけでは終わりません。コード全体を修正し、データフローを再調整し、例外処理やテストも繰り返す必要があります。結果として、AIアプリは作ることよりも、維持し改善し続けることの方が難しくなります。
従来のノードベース構造の限界
一般的なワークフローツールでは、各サービスが1つのノードとして提供されます。例えば、OpenAIノード、Google Sheetsノード、Slackノード、Notionノードのように、サービス名を基準にノードが構成されます。
この方式は、単純な自動化には便利です。しかし、生成AIアプリケーションを作る場合には明確な限界があります。
サービスが変わればノードも変わり、
ノードが変われば入力と出力の構造も変わり、
最終的にはフロー全体を再修正しなければならないケースが多くなります。
つまり、ワークフローの中心が「何を実現したいのか」ではなく、「どのサービスを使うのか」に置かれてしまうのです。
HyperFlow AIはこの点を異なる視点で捉えています。AIワークフローにおいて重要なのは、特定のサービス名ではなく、そのノードが果たす役割です。
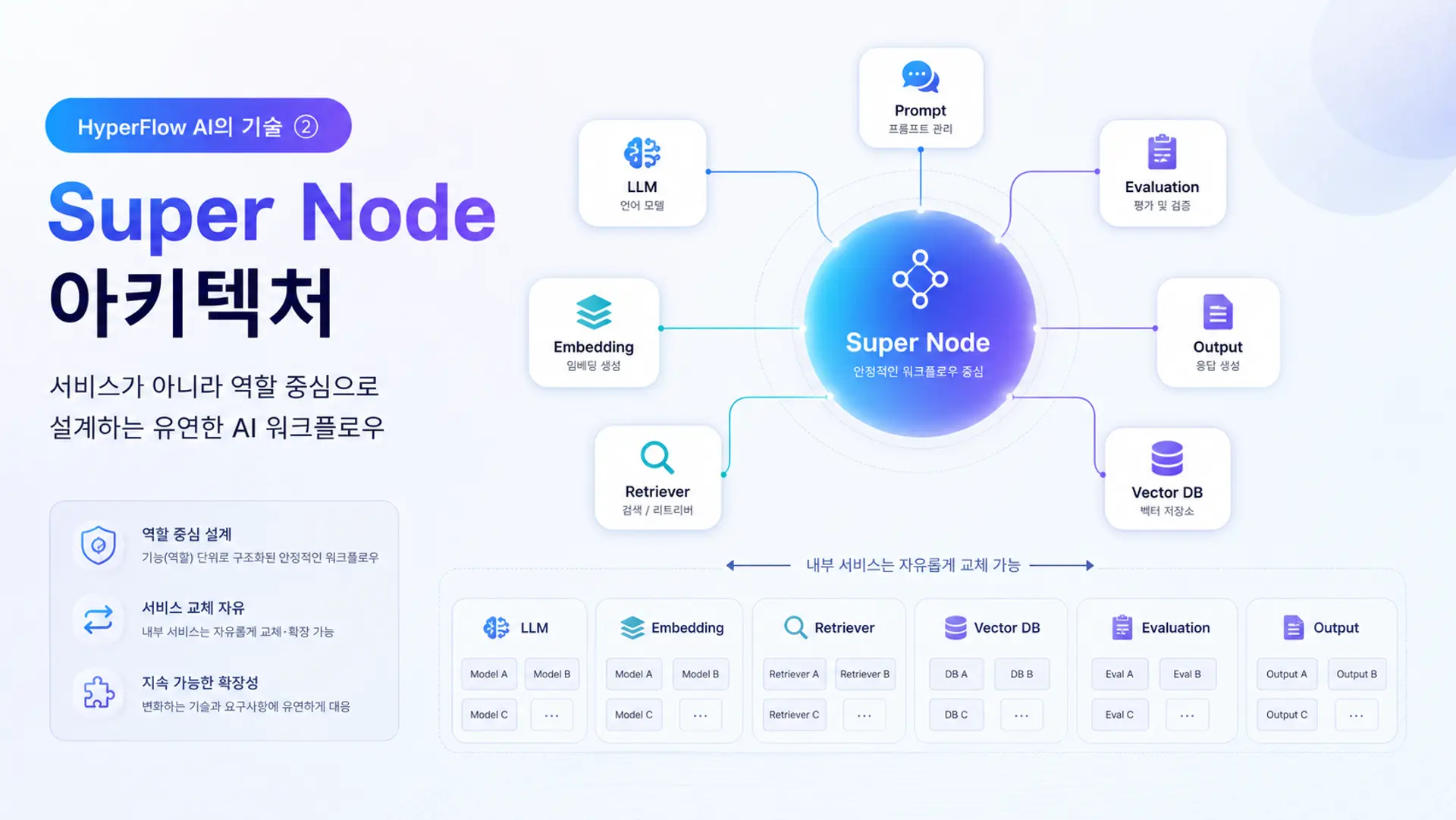
HyperFlowのSuper Nodeとは何か
HyperFlowのSuper Nodeは、特定の1つのサービスに結びついたノードではありません。代わりに、1つの機能的な役割を中心に設計された抽象化されたノードです。
例えば、ユーザーが「LLMを呼び出す」という作業を行うとします。従来の方式では、OpenAIノード、Claudeノード、Geminiノードがそれぞれ別々に存在する場合があります。しかしHyperFlowでは、これらすべてを1つのLLMという役割として扱うことができます。
ユーザーはフローの構造を維持したまま、内部でどのモデルを使用するかだけを選択または変更できます。
OpenAIからClaudeへ
ClaudeからGeminiへ
商用モデルからオープンソースモデルへ
モデルが変わっても、ワークフロー全体の構造はそのまま維持されます。これがSuper Nodeアーキテクチャの核心です。
サービスではなく役割を中心に設計する
Super Nodeの最大の利点は、ワークフローをより長く維持できる構造にすることです。AI開発環境において、特定のツールやモデルが永遠に最適な選択であり続けることはありません。コスト、速度、性能、セキュリティポリシー、顧客要件に応じて、いつでも変更が必要になる可能性があります。
そのためHyperFlow AIは、最初から特定のベンダーに依存する方式ではなく、役割中心の構造を選択しました。
LLM呼び出し
文書検索
エンベディング生成
データ前処理
条件分岐
結果評価
出力生成
これらの作業は、特定のサービス名よりもはるかに長く持続する概念です。HyperFlowはこの機能的な役割を基準にワークフローを構成し、実行段階で必要なサービスやモデルを接続します。
その結果、ユーザーは技術の変化に合わせて内部構成要素を変更しても、フロー全体を最初から作り直す必要がありません。
AIの実験と運用をより速くする構造
Super Nodeは実験プロセスにおいても大きな強みを発揮します。生成AIアプリケーションは、一度作って終わるシステムではありません。プロンプトを変更し、モデルを切り替え、検索方法を調整し、出力形式を改善するプロセスが継続的に繰り返されます。
従来の方式では、こうした実験の一つひとつが開発作業に近いものでした。モデルを変更するためにはコードを修正し、検索構造を変えるためにはパイプラインを再接続する必要がありました。
しかしHyperFlowでは、Super Nodeを通じて同じフロー内でさまざまな構成を素早く比較できます。
どのLLMがより適しているのか
どのエンベディングモデルがより良い検索結果を出すのか
どのプロンプト構造がより安定した回答を生成するのか
どのパラメータの組み合わせがコスト対効果に優れているのか
こうした実験を、コード修正ではなくフロー設定の変更によって実行できます。これによりAI開発は、より速く、より再現性が高く、より体系的なプロセスへと変わります。
技術資産として残るワークフロー
HyperFlow AIが重視しているのは、単純な自動化ではありません。私たちが作るワークフローが、時間が経っても継続的に活用できる技術資産になることです。
AIモデルは変わる可能性があります。
API価格も変わる可能性があります。
顧客要件も変わる可能性があります。
しかし、業務の構造や問題解決の方法は簡単には消えません。
Super Nodeアーキテクチャは、この変わりにくい構造を中心に置き、変化する技術要素を柔軟に置き換えられるようにします。これにより、HyperFlowで作成されたAIワークフローは、単なる一回限りの実装ではなく、企業内部に蓄積される運用可能なIPとなります。
HyperFlow AIが目指す開発方式
HyperFlow AIの目標は、ユーザーにより多くのコードを書かせることではありません。むしろ、複雑な技術要素を構造化し、ユーザーが本質的な課題解決に集中できるようにすることです。
どのデータを使用するのか
どのような判断フローを作るのか
どのような成果物を生成するのか
どのように検証し改善するのか
HyperFlowは、こうした問いに集中できる環境を提供します。Super Nodeは、その基盤となる中核構造です。
生成AIの時代には、単にAIを接続するだけでは十分ではありません。重要なのは、変化する技術環境の中でも継続的に改善され、運用できる構造を作ることです。
HyperFlow AIのSuper Nodeアーキテクチャは、まさにその構造を可能にします。AIアプリケーションをより簡単に作り、より速く実験し、より長く運用できるようにすること。これこそが、HyperFlowがSuper Nodeを通じて解決しようとしている核心的な課題です。
