
HyperFlow AIのパラメータフロー
HyperFlow AIは、プロンプト、モデル設定、検索条件、出力形式までをコードではなくフローの中で管理し、より速く安定したAIの実験と運用を可能にします。
AIの性能はモデルだけで決まるものではありません
生成AIアプリケーションを作るとき、多くの人はまずどのモデルを使うかを考えます。OpenAI、Claude、Gemini、オープンソースモデルなど、どのLLMを選ぶかは確かに重要な問題です。しかし、実際のサービスにおけるAIの品質は、モデルだけで決まるものではありません。
同じモデルを使っていても、プロンプトをどのように作成するか、検索範囲をどこまで設定するか、温度値をどのように調整するか、結果をどの形式で出力するかによって、回答の品質は大きく変わります。
つまり、生成AIアプリケーションの性能は、モデルそのものだけでなく、その周辺にある多くの設定値、すなわちパラメータの組み合わせによって決まります。
パラメータが分散すると運用が難しくなります
従来の開発方式では、こうしたパラメータが複数の場所に分散していることがよくあります。プロンプトはコードの中にあり、モデル設定はAPI呼び出し部分にあり、検索条件はデータベースクエリに含まれ、出力形式は別の後処理ロジックで管理されます。
最初は大きな問題に見えないかもしれません。しかし、実際の運用が始まると状況は変わります。
回答が長すぎる場合はプロンプトを修正する必要があり、検索結果が不正確な場合は検索条件を調整する必要があります。コストが高くなればモデル設定を変更する必要があり、顧客が求める形式が変われば出力構造も修正しなければなりません。
このとき、設定値がコードのあちこちに分散していると、小さな修正であっても開発作業になります。結果として、AIアプリケーションは時間が経つほど実験しにくく、改善しにくい構造になってしまいます。
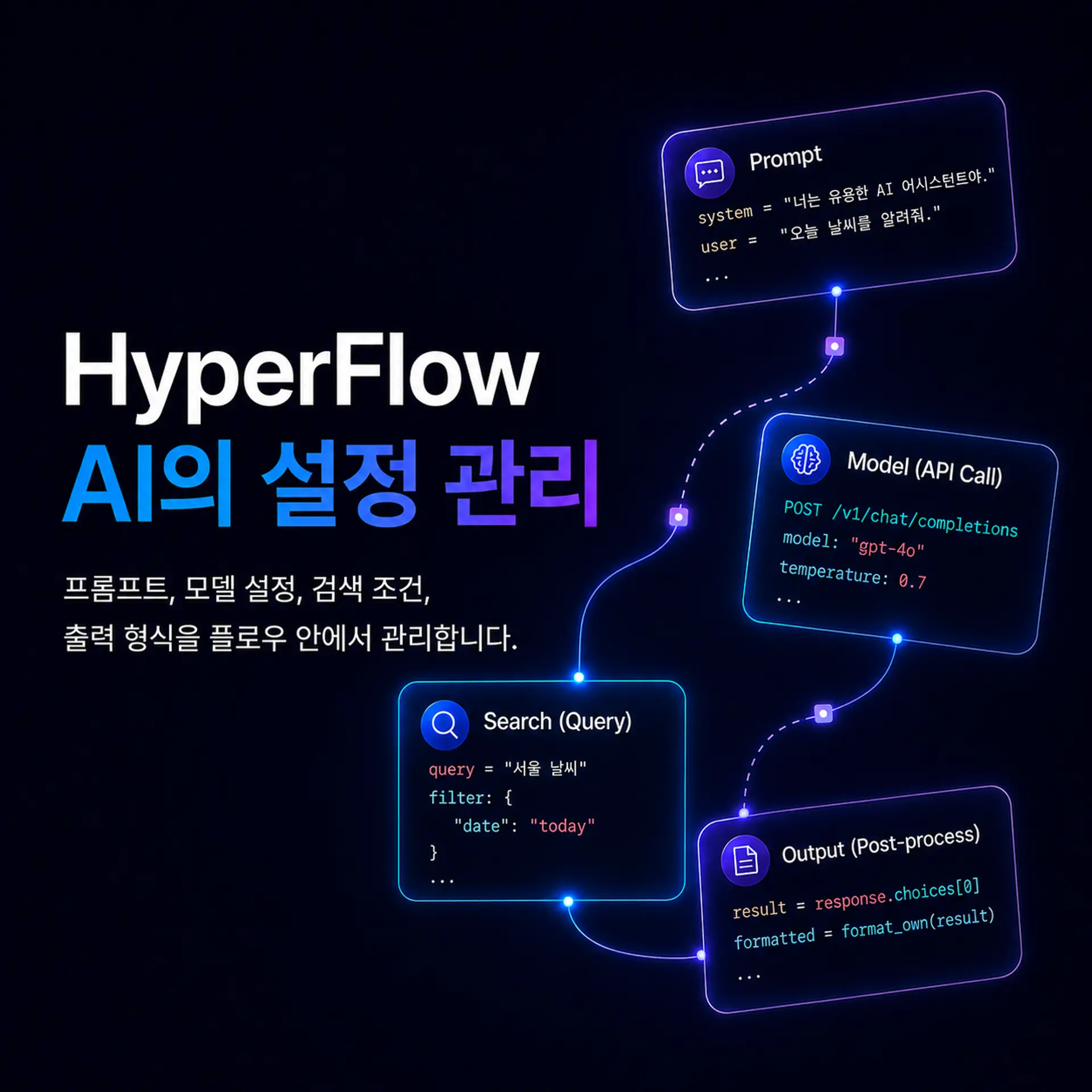
HyperFlowはパラメータを「フロー」として扱います
HyperFlow AIは、パラメータを隠れた設定値として扱いません。代わりに、フローの中で接続され、調整される一つの流れとして扱います。
HyperFlowのフローグラフの中では、プロンプト、モデル設定、検索条件、出力形式、条件分岐といった要素がそれぞれ独立して管理されながらも、一つの実行フローの中で自然につながります。
ユーザーは、コードの中に隠れている設定を探して修正する必要はありません。どの入力が入り、どの検索を経て、どのモデル設定で回答が生成され、どの形式で結果が出力されるのかを、フロー上で直接確認し調整できます。
実験がより簡単になります
生成AI開発は、一度作って終わるものではありません。プロンプトを変更し、モデルを比較し、検索範囲を調整し、出力形式を変えるといった実験を継続的に繰り返す必要があります。
HyperFlowでは、こうした実験をコード修正ではなく、フロー設定の変更によって実行できます。
たとえば、同じ質問に対して異なるプロンプトを比較したり、同じ検索結果を複数のモデルに渡して回答品質を確認したりできます。検索結果の数を変えて精度を比較したり、JSON、表、要約文など、さまざまな出力形式をテストすることもできます。
このようにパラメータをフローとして扱うことで、AIの実験はより速く、より再現性が高く、より体系的なプロセスになります。
チームで管理するAIシステム
パラメータがコードの中にだけ存在すると、AIシステムは特定の開発者に依存することになります。しかしHyperFlowでは、パラメータがフローの中で構造化されるため、チーム単位での運用がしやすくなります。
マーケターはブランドトーンに合わせてプロンプトを改善でき、企画担当者はユーザー条件に応じた分岐構造を設計できます。運用担当者は頻繁に発生するエラーケースを基準にフローを調整でき、開発者はシステム全体の安定性と拡張性に集中できます。
AIアプリケーションは、もはや一人の開発者が管理するコードではありません。チーム全体で改善していく運用資産になります。
AI品質管理はパラメータ管理から始まります
優れたAIサービスを作るためには、良いモデルを選ぶだけでは不十分です。プロンプト、検索条件、モデル設定、出力形式、条件分岐までを一緒に管理してこそ、実際の業務で使える安定したAIシステムになります。
HyperFlow AIは、これらすべてのパラメータをコードの中に隠すのではなく、フロー上に可視化します。これにより、ユーザーはAIシステムがどのように動作しているのかを理解し、必要な部分を素早く調整し、より良い結果を繰り返し作り出すことができます。
パラメータを一つの流れとしてつなげること。これが、HyperFlow AIが生成AIアプリケーションをより柔軟で、より安定し、より運用しやすいシステムにする方法です。
